

英伟达这个芯片,依然难逢敌手
 Newseeders 合作伙伴
Newseeders 合作伙伴随着机器学习越来越多地进入社会的每一个角落,相应的训练任务也成为了云端数据中心最关键的运算负载之一,同时这也推动了半导体相关芯片市场的蓬勃发展。在云端训练芯片领域,虽然一直有不同的挑战者,但是Nvidia一直保持着龙头的位置。从2012年深度学习复兴,依靠Nvidia GPU的CUDA生态成功克服训练效率难题并成功掀起这一代人工智能潮流之后,Nvidia的GPU一直是训练市场的首选芯片。
上周MLperf公布的最新训练榜单也再次印证了Nvidia的稳固地位。MLPerf是由机器学习业界的行业组织ML Commons牵头做的标准榜单,其中训练榜单的具体测评方法是ML Commons提供一些业界最流行的机器学习模型的训练任务,而不同的机构会自行去使用不同的处理器和AI加速芯片配合相应的软件框架去搭建系统执行这些训练任务,并且将结果提交到MLPerf来汇总和公布。每过一段时间,该榜单都会更新一次以包括新的芯片以及新的训练任务。在最新的6月29日公布的MLPerf训练2.0版本的结果中,Nvidia的领先地位可以从榜单中的两个地方看出:
首先是使用Nvidia GPU提交结果的数量。在这次MLPerf的最新训练榜单中,绝大多数(90%以上)机构提交的训练结果都是基于Nvidia的GPU做训练加速,而如果再仔细看结果,会发现Nvidia的GPU是和不同的机器学习训练框架兼容性最好的。例如,Google、Intel和GraphCore都上传了使用非Nvidia GPU的结果(Google使用TPU v4,Intel使用Habana Gaudi芯片,而Graphcore使用Bow IPU),但是这些竞争芯片对于深度学习框架支持的广度都不及Nvidia——基本上所有深度学习框架都会支持Nvidia的GPU,但是支持其他芯片的深度学习框架种类则有限。这也从一个角度说明了Nvidia在生态上的领先。
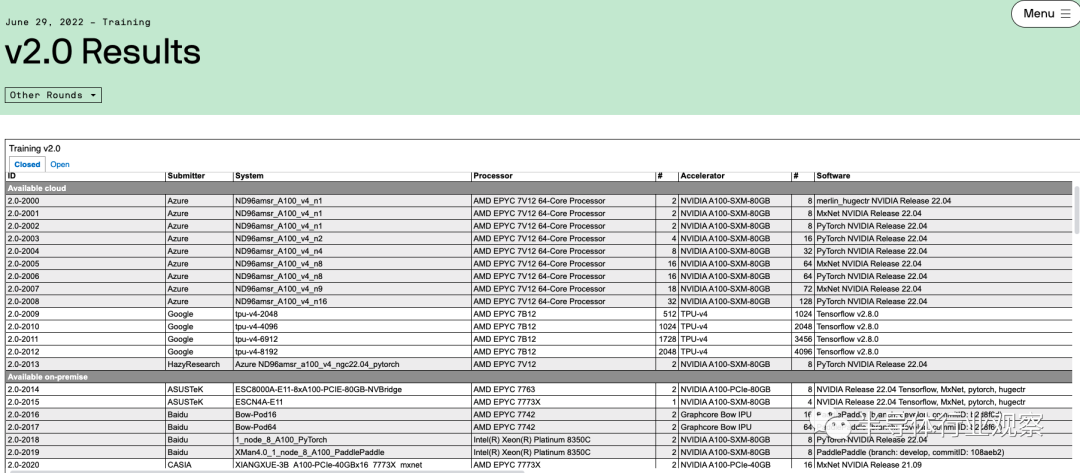
其次是性能上的比较。值得注意的是,本次绝大多数机构提交的基于Nvidia GPU的结果都是基于Nvidia A100 GPU,换句话说这已经是两年前的芯片的结果了(Nvidia官方宣布基于下一代GPU H100的结果将会在下一次MLPerf榜单更新时提交),但是其结果仍然很有竞争力,相较于其他更新的芯片的结果并不遑多让。例如,相比最新的Google TPUv4,在大规模语言模型预训练(BERT)任务上,同样使用4096张加速卡TPU v4需要的时间是0.179分钟,而Nvidia A100需要的时间是0.206分钟,相差并不大。相比Intel Habana Gaudi2,同样使用8张加速卡Nvidia A100 的BERT训练结果是17.624分钟,而Habana Gaudi2需要的时间是17.209分钟。相比Graphcore Bow IPU,在BERT任务上128张A100的训练时间是2.655分钟,而Bow IPU需要4.415分钟。在一些物体识别任务中,Habana Gaudi2的性能确实强于A100,但是这样的优势在Nvidia H100发布后是否还能保持还有很大的不确定性。
Nvidia的软硬件生态是关键护城河
如前所述,Nvidia目前仍然在机器学习训练市场可以说是独孤求败,并没有受到强大的挑战。我们认为,这得益于Nvidia在芯片和软件方面的全面能力,而这从另一个角度又与人工智能芯片发展的规律相得益彰。
首先,人工智能的发展规律中,人工智能模型始终和相关的加速硬件一起发展,也正因为这个原因,有能力掌握软硬件协同设计的公司将会有巨大的优势。即使单从芯片设计的角度来看,人工智能加速芯片中的架构设计也是极其重要,从性能提升角度比芯片的半导体工艺要更重要。
纵观MLPerf公布的榜单,从第一个榜单公布到现在的时间周期内,摩尔定律主导的芯片性能(时钟频率)提升约为四倍,但是芯片对机器学习任务的处理能力却增强了四十倍,由此可见芯片架构以及软硬件协同设计恰恰是人工智能加速芯片的核心要素,而半导体工艺提升只是一个辅助因素。在这个领域,Nvidia确实具有巨大的优势,因为Nvidia在拥有强大的芯片架构设计团队来为人工智能模型设计芯片架构的同时,也拥有很强的软件团队来优化在芯片上的人工智能模型运行效率,两者相结合确实威力无穷。
纵观Nvidia针对机器学习的GPU设计,其软硬件协同设计的思路可以说是一以贯之;在深度学习还未成为主流的时候,Nvidia就相当具有前瞻性地大力投入CUDA通用计算(包括软件架构以及相应的芯片架构支持)让GPU在曾经CPU一统天下高性能计算领域的打出一片天,而在深度学习成为主流之后,Nvidia的做法并非一味暴力增强算力,而是通过有针对性地优化来以最佳的效率提升性能,其中的例子包括支持混合精度训练和推理,对于INT8的大力支持,在GPU中加入Tensor Core来提升卷积计算能力,以及最新的在H100 GPU中加入Transformer Engine来提升相关模型的性能。这些投入都包括了软件和芯片架构上的协同设计,而同时也收到了很好的回报,使得Nvidia能使用最小的代价(芯片面积,功耗)来保持性能的领先。
时至今日,Nvidia的GPU架构已经能在通用性(即对于各种模型算子的支持)和效率(即对于重要模型算子的运行效率)上获得了很好的平衡,因此即使在“GPU架构并不是最适合机器学习模型加速”的观点盛行多年后,Nvidia的GPU仍然是机器学习训练市场的最优选择——因为其他的加速芯片对于某些算子做专用优化之后往往通用性无法顾及,而通用型的加速芯片则很难与拥有巨大系统团队支持的Nvidia设计的GPU性能相抗衡。
在性能领先之外,Nvidia在软件生态上也拥有很高的护城河。如前所述,Nvidia的芯片架构能够在通用性和效率之间实现一个很好的平衡,而在这个基础上,一套易用且能充分调动芯片架构潜力的软件生态则会让Nvidia在机器学习模型社区拥有巨大的影响力——这使得模型设计者在设计模型时将会自发针对Nvidia的GPU做模型优化,从而更进一步提高Nvidia的竞争力。Nvidia拥有CUDA这样成熟而性能良好的底层软件架构,因此目前几乎所有的深度学习训练和推理框架都把对于Nvidia GPU的支持和优化作为必备的目标,相比较而言对于其他竞争芯片来说,软件生态方面的支持就少得多了(例如对于Google TPU的主要生态支持来自Google自己的TensorFlow,然而TensorFlow目前在人工智能社区使用人数正在慢慢落后于Pytorch,这也成为TPU在生态上的一个瓶颈),这也成为了Nvidia GPU的一大护城河。
未来的市场格局会如何发生变化?
目前Nvidia在人工智能训练市场的领先地位仍然非常稳固,但是随着挑战者的出现,在未来市场格局有可能会出现变化。我们认为,可以把竞品分成几类,而不同的竞品也将会有不同的市场格局影响。
第一类是科技公司自研芯片:他们走和Nvidia相似的路线(即软硬件结合设计),通过调动自身对于人工智能模型的深入理解,来实现有竞争力的芯片。另一方面,这类芯片通常不需要在生态方面与Nvidia竞争,因为其主要的客户就是这些科技公司自己,因此从市场格局上来说会部分减少这些公司对于Nvidia的依赖度,但是总体来说并不会对Nvidia直接竞争。典型的例子是Google的TPU系列,Google本身对于人工智能的研发能力甚至比Nvidia更强,那么通过这样的积累结合软硬件协同设计就能实现性能很强的自研芯片,但是这样的芯片并不会对外出售也不会在市场上和Nvidia正面竞争,因此对市场格局影响不大。
第二类是在芯片架构设计上做出和Nvidia不同的取舍,从而在某些模型中实现超过Nvidia的性能(包括运行速度,功耗,能效比等),从而和Nvidia实现差异化竞争。Intel Habana和Graphcore都是属于这类思路,他们的芯片在一些重要模型类型中有相对Nvidia更高的性能或效率,从而随着这些模型相关算力需求增大,也有更多理由来使用这些芯片。这些芯片将会在模型运行效率的维度(而非通用平均性能)和Nvidia有竞争,但是也不太可能颠覆Nvidia。
第三类是直接复制Nvidia的整个技术链条,和Nvidia打白刃战,并通过实打实的全方位性能和性价比等因素来获得市场。这样做的公司主要是AMD,目前AMD的MI系列高性能计算GPU虽然还没有获得广泛应用,在这次MLPerf上也没有相关的结果,但是事实上整体高性能计算和云端计算市场对于这类Nvidia的替代性产品有很强的需求,因为Nvidia成为该领域的单一供应商将会对供应链造成风险,同时也降低系统公司的议价能力。AMD在该领域的努力正在慢慢获得业界的支持,在主流深度学习框架(例如PyTorch)已经加入了对于AMD系列GPU后端的支持,而相信云端计算厂商也在逐渐增加基于AMD GPU机器学习系统的投入。我们认为,AMD可能会是该领域对于Nvidia的最有力竞争对手,也最有可能获得较大的市场份额。



