

互联网巨头都盯上了这颗芯片
 Newseeders 合作伙伴
Newseeders 合作伙伴过去几年来,在需求的推动下,互联网造芯早已家喻户晓。尤其是过去几年云计算、数据中心和人工智能的火热,全球*的互联网企业似乎都殊途同归,走向了AI芯片、CPU和DPU等芯片的自研道路。与此同时,他们还会根据各自业务的不同,针对性地打造了不同的芯片矩阵。
在我们还对互联网造芯近年发展之快感到惊叹之余,诸如谷歌、Meta、字节跳动和腾讯等互联网公司又都无一例外地盯上了一款芯片:那就是视频处理芯片VPU(Video Processing Unit)。
谷歌、腾讯、字节和Facebook
均已着手自研
2021年4月,谷歌发布了自研的Argos VCU(VCU是谷歌的称法)。Argos有10个用于处理视频的内核,这些内核放置在一个相当大的散热器下,每块板上放置两个芯片。谷歌声称它可以将计算效率提高20到33倍,以往处理4K视频要几天,现在只需数小时就行。Argos的研发成功替代了多达数千万颗英特尔CPU,仅CPU就节省超过200亿人民币的资金投入规模。在构建这个芯片的过程中,谷歌甚至创造了他们自己的EDA工具,叫做Taffel。

谷歌Argos VCU
我们正在进入一个音视频蓬勃发展时代,表现为视频用户数激增、视频产生量巨大,视频越来越难以被压缩和处理。从2003年发展至今,有许多不同的视频标准和编解码器(如下图所示),如果编解码器在压缩视频时的效率越高,那么最终的文件尺寸更小,流更小。

图源:谷歌在Hot Chips 33 上的演讲内容
谷歌的Argos芯片能助力其使用VP9的视频编码器,相比前一代H.264,其视频压缩效率提高了40%。VP9是一种更复杂的视频编解码器,它允许视频文件变得更小并保持相同的图片质量,它还可以存储相同大小但质量更高的视频。VP9允许Google节省大量带宽,这些带宽通过他们的内容交付网络从数据中心流出给消费者,这反过来又大大降低了他们的成本。AV1是更*别的视频编码方式,将比VP9再提高30%-40%。更*别的压缩通常需要更多的计算。
根据SemiAnalysis的消息来源,下一代Argos已经在开发中。它将能够实现在CPU或GPU 上难以支持的 AV1 格式,将实现进一步的存储和带宽节省。此外,他们还计划开始在新芯片上添加机器学习推理硬件。最后,他们还将在附加卡本身上添加网络,以提高效率并减少与主机 CPU 的通信。这将允许他们自动生成视频字幕,检查是否违反服务条款,甚至允许在 YouTube 和 Google 照片上启用视频搜索。
今年6月份,腾讯云发表了《腾讯的芯事》,从中我们了解到,腾讯自研的视频转码芯片——“沧海”,已于2022年3月5日流片回来,并点亮。这是腾讯的第三款芯片,也是完全自主研发的*款芯片。腾讯的沧海小分队的目标就是要做一款业界最强的视频转码芯片,把压缩率发挥到*。沧海芯片采用12nm工艺,实现了以更小的数据量、更小的带宽提供相同质量的视频,压缩率相比行业*表现提高了30%以上。
字节跳动造芯近来再次掀起一波关注高潮。据了解,字节跳动从三年前开始做视频编解码硬件研发,去年下半年开始组建SoC团队,年初FPGA上线。7月20日,字节跳动副总裁杨震原在“2022火山引擎原动力大会”上接受媒体采访时确认,字节跳动正在开展自研芯片,主要用于自身视频推荐业务。研发团队将为字节跳动大规模视频推荐服务专用场景定制硬件优化,如视频编解码、云端推理加速等,以期提升性能,降低成本。
除了字节以外,另一个国内视频巨头快手也在相关视频芯片产品上有布局。据笔者了解,他们的相关芯片已经会片,或许应该能看到更多的信息披露。
此外,Facebook母公司Meta也正在寻求“控制关键技术并减少对现有芯片供应商的依赖”。据悉,其也正在开发定制服务器芯片,其中一款AI推理芯片主要用于推荐算法等;另一款则主要进行视频转码任务,以提高Facebook用户观看录制和直播视频的质量。而且Facebook还聘请了一位来自英特尔的资深网络芯片工程师Jon Dama来领导这家互联网巨头的基础设施硬件工程组的芯片设计工作。
CPU和GPU不再经济,
VPU或将大放异彩
当下,随着互联网内容的不断更新迭代,视频流媒体已开始取代文字、图片等形式,直播、点播、短视频等视频应用正在“侵蚀”每个年龄阶段的人,视频流媒体约攻占互联网80%的流量,如国外的Youtube,国内的抖音、快手等短视频。网络已经在内容上走向去中心化的路线,用户每分钟向Youtube上传超过700小时的YouTube视频,抖音、快手以及腾讯微视频等亦是如此。消费者更多的是将时间花在了用户生成的内容上。
在这个过程中要做的工作越来越复杂,视频的分辨率、质量和带宽消耗等直接决定了用户的粘性。抖音这几年来是短视频领域的赢家之一,很大一个原因在于其能对每个人进行定制化的推送,背后有着强大的推荐机制。用户对超高清视频(4K/8K)的追求越来越高,但也带来了更高的编解码算力需求和CDN带宽成本。
多年来,英特尔的CPU+软件的视频解码/编码方案一直主导着流媒体市场,但是随着视频流媒体对高质量视频的需求不断增长,CPU将不再具有经济价值,而且会消耗太多的能耗和空间。GPU虽然有稍微更好的TCO(总拥有成本),但缺点是较低的利用率和较低的工作负载灵活性。使用GPU对于某些应用程序来说,运行驱动程序栈是一件复杂而混乱的事情,各种版本的Linux或Windows都不能正常工作,这类软件问题阻碍了英特尔、英伟达等GPU方案的发展,比如英特尔被取消的Xe HP tile GPU架构。英特尔的Xe-HP计算GPU是该公司多年来启动的*款高性能独立GPU,也是英特尔向公众展示的*款独立Xe GPU。

英特尔的Xe-HP计算GPU
显然,CPU和GPU都已经不适合处理巨量的视频业务,因此VPU这种专用的视频处理芯片应运而生。在某种意义上,VPU比其他编码方法更灵活。

图源:Semianalysis
VPU是结合AI技术专门面向视频场景优化设计的视频加速器,内置视频编码加速专用功能模块,具有高性能、低功耗、低延时等特性,能为视频行业应用带来高效能的加速计算。
图源:Semianalysis
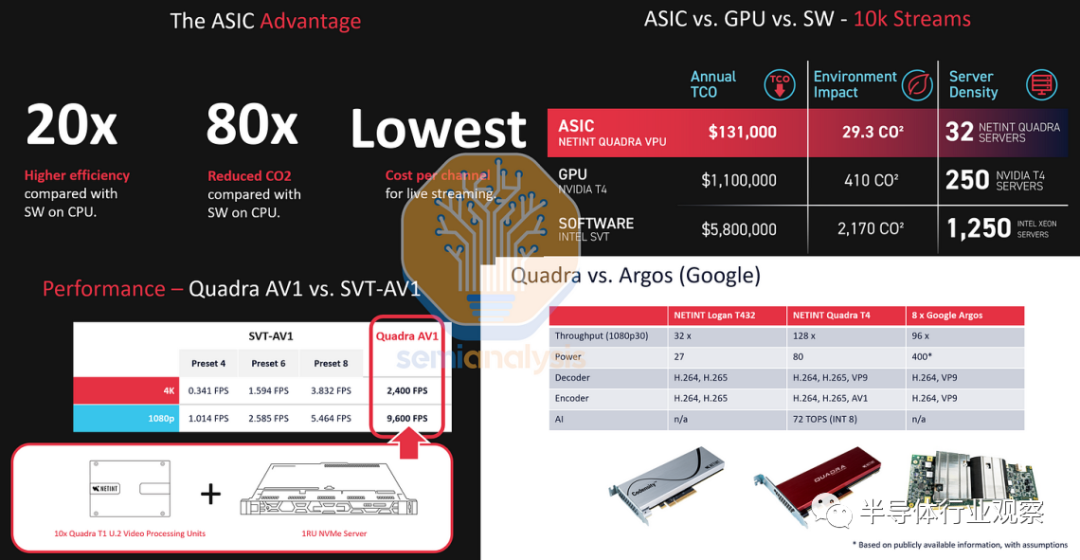
一般来说,ASIC需要在它们的目标工作负载中提供高一个数量级的更好的能力才能被行业认可。而据SemiAnalysis对国产VPU芯片初创企业镕铭微电子(NETINT)的分析,相比于CPU和GPU,VPU的密度和功耗是CPU和GPU无法比拟的。下图是使用HEVC编解码器,镕铭微电子的VPU碾压英伟达的上一代T4(有更新的基于安培GPU)和英特尔的Skylake/Cascade Lake服务器。其设计的Codensity系列VPU芯片已经在中国超过90%的一线互联网和视频内容客户中得到大规模部署,并在大量海外客户如微软、IBM等企业中得到了广泛应用,他们还面向全球推出世界*款支持AV1编码能力的芯片级解决方案。


镕铭微电子VPU产品
(图源:镕铭微电子)
另外,据相关报道,一家名为涌现科技的公司在这方面也有布局。该公司表示提供的Seirios视频编解码加速解决方案,核心的ASIC视频编解码芯片是由涌现科技研发团队自主研发的先进制程芯片,通过将其安装在执行编码和转码的视频处理服务器上,可以在不改变服务器配置的情况下提升处理性能。减轻数据中心服务器的多媒体处理负担,降低整体功耗和成本。
从谷歌自研VPU所获得的好处,我们也可以看出为何互联网厂商纷纷发力VPU这颗芯片:一方面,互联网是最讲求TCO(总拥有成本)的地方,使用VPU将大大减少对CPU的使用量;另一方面,能够根据自己的需求,打造更低的功耗和更快的芯片,这也将加强他们的战略优势。还有一个有利条件是,他们这些互联网厂商都有自己的视频产品,丰富的多媒体应用场景,以及云覆盖的众多直播互动头部客户,将为他们的研发提供得天独厚的分析和验证条件。再者,互联网巨头对这个赛道的看好,足以见得VPU这个市场的广阔前景。
写在最后
由于VPU芯片是一个对场景处理技术要求很高的产品,所以目前主攻ASIC VPU的芯片供应商中似乎并不多。整体而言,目前只有少数几家厂商真正做到了大规模实际应用,互联网厂商自研的产品到真正可落地实际应用还有2-3年的时间。
中国的各类视频应用已然走在时代前列,同时还有庞大的用户群体,不止如此,VPU的市场应用场景非常多,随着5G、移动端视频、云游戏、云桌面、VR/AR、元宇宙等行业的高速扩张,市场对专用视频处理芯片的需求呈现爆发式增长,专用于视频处理的ASIC芯片或将迎来长周期的蓝海市场。
有研究分析,预计在未来几年内,VPU市场规模可能将达千亿美金。从CPU到GPU,再到DPU,而现在一个属于VPU的时代似乎正在悄然而来,目测未来这个市场应该会扎入更多玩家。
►本文参考资料:
https://semianalysis.com/meet-netint-the-startup-selling-to-datacenter-vpus-to-bytedance-baidu-tencent-alibaba-and-more/



